.avif)
Does SAST Deliver? The Challenges of Code Scanning



I love the idea behind Static Application Security Testing (SAST) tools — they aim to create an utopian world clean from application vulnerabilities.
If Dynamic Application Security Testing (DAST) tools look at your application to find doors and windows left open to intruders, SAST tools try to prevent them from being opened in the first place. SAST tools are code scanners that alert developers if they create lines of code that are vulnerable, and provide recommendations on how to fix them. Some of these tools even have IDE integrations so developers can secure the code while writing it!
Sounds amazing, right?
On paper, SAST is a great technology but in reality faces many challenges that lead to a high volume of false positives and false negatives. This article discusses at a high level how SAST tools work. Disclaimer: I have never built a SAST tool. I’m writing from the perspective of a curious pen-tester who has used different SAST tools to understand their weak points.
On top of that, I’ve performed many pen-tests where I had only code access, with no access to a running instance of the application. (Working with government organizations is so much fun.) Many of the challenges faced in this type of pentest are very similar to the challenges of SAST. The one thing we need to understand about code scanning is this: Even if you find something that clearly looks like a security bug, in many cases it doesn’t expose a real vulnerability.
As we discussed in a previous article on DAST, when performing an active pentest (or using a DAST tool) you just need to “strike” once. Usually a simple evidence is enough to prove that the code is vulnerable. For example: you stole details of another user in the system, you managed to access sensitive SQL tables and so on. In the field of code scanning, it doesn’t work the same way. After you find a line of code that looks like a security bug, two things need to be proven: 1) this piece of code is accessible by the client and 2) there are no preceding lines of code that prevent exploitation of the security bug.
Process 1. Find Dangerous Code Patterns
The first process is finding the piece of code that screams “I’m vulnerable.” These are usually obvious and contain one or a few lines of code.
Let’s see a few examples:
XSS

SSRF

There are a few different approaches to finding these dangerous code patterns.
- Function names. Some functions are inherently dangerous by design, like the “open” in Ruby, or any function that allows you to execute shell commands.
- Pattern matching and Regexes. Some frameworks, like Semgrep, heavily rely on pattern matching for known code patterns
Process 2. Understand the Code Flow
Applying regexes to find potential vulnerable lines of code is nice, but not enough by itself. A good code scanner needs to understand the code flow in order to highlight vulnerabilities that are exploitable.
What should be the main focus areas?
Safe vs. unsafe input — Taint Analysis
Vulnerabilities usually happen because of an input that is used in an unsafe manner (dangerous code patterns). But not all inputs are necessarily evil. Inputs that can not be controlled by the client are safe inputs.
Example of a safe input:
SQLi from config

Since the “current_version” parameter is a string taken from the config file, we can consider it as safe, and the code isn’t vulnerable to SQLi.
Code scanners use Taint Analysis to differentiate between safe and unsafe inputs. Taint analysis, in a nutshell, is the process of identifying unsafe sources for input, following unsafe inputs from these sources throughout the code, and understanding if they reach dangerous code patterns.
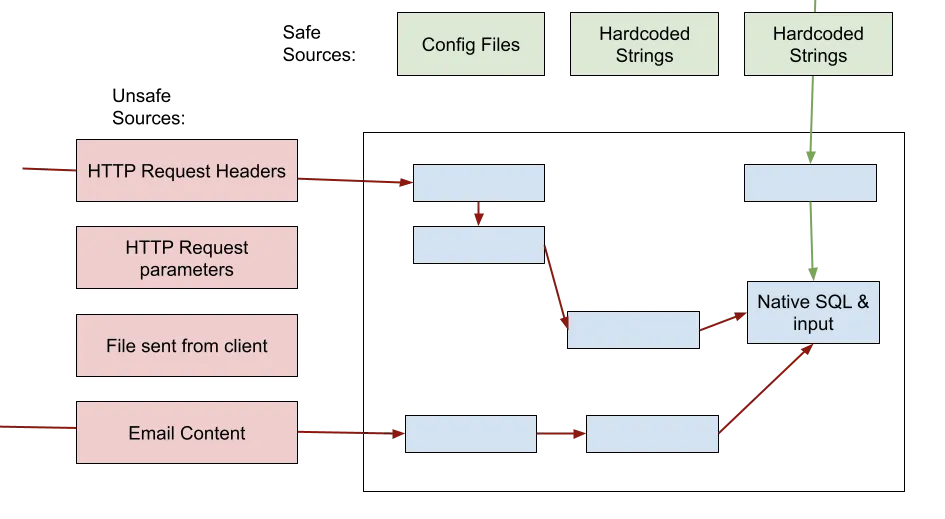
Identifying unreachable areas in the code
Sometimes a piece of code can be vulnerable but not exploitable. A classic example is a vulnerability in a third-party library that’s never used. Another example is unreachable code, which can never be executed. A good SAST tool should be able to tell which of the vulnerabilities are in reachable code and prioritize them.
Process 3. Identify Input Validation
There are various ways to write vulnerable code, but even more ways to make it secure. Input validation and input sanitization are legit ways to secure application code.
If you perform whitebox pen-test and find this line of code:
SQL.execute(“SELECT * FROM users_table where age = “ + params[:age])
You might declare, “OMG I just found a SQLi!!!.” But not so fast, my friend. Since we test an application with complex code flow, there are many ways developers could validate the input and protect the app before this line of code is even called.
For example:

The code above isn’t vulnerable to SQL injection because the developers validated that the “age” parameter is an integer.
In the case of Server-Side Request Forgery (SSRF), developers might have created an allow list that contains only a small set of URLs. If the URL that’s sent from the client isn’t on the allow list, an error would be returned. A SAST tool needs to make sure that no input validation or sanitization has been performed on the unsafe input from the client. This is where it becomes very tricky, because of the following reasons:
Not all input validations are born the same
The type of the required input validation to protect the app depends not only on the type of vulnerability, but also on the specific occurrence.
Let’s take for example the following dangerous code pattern (where the DB is the last version of MSSQL).:

One approach to protect against SQLi here is by doubling up apostrophes. If you take the usafe input, and replace each apostrophe with two apostrophes ( ‘ --> ‘’ ), the code is secure*.

On the other hand this technique won’t help if the SQL statement looks a bit different, something like:

The code will still be vulnerable to SQLi, because doubling up apostrophes works only when the unsafe input is added inside a SQL string, between two single quotes.
*There’s an old technique called SQL smuggling to bypass this type of protection, but it doesn’t work in most modern DBs.
Input validation can be done in different places
Input validation is a mechanism that performs string matching. It can be implemented in many ways and places — the same code class, an external library, or even in a different component.
Understanding what is the required validation, based on the dangerous code pattern, and then identifying the potential places and methods where validation can happen, is an extremely challenging process.
Some common examples where SAST may fail to detect input validation:
- The validation happens on the API Gateway, based on a swagger file. The scanner knows only the code, with no idea what an API gateway or a swagger file are.
- In microservices. The vulnerable code is written in Java, and the input validation happens in a microservice written in Python. The SAST supports only Java.
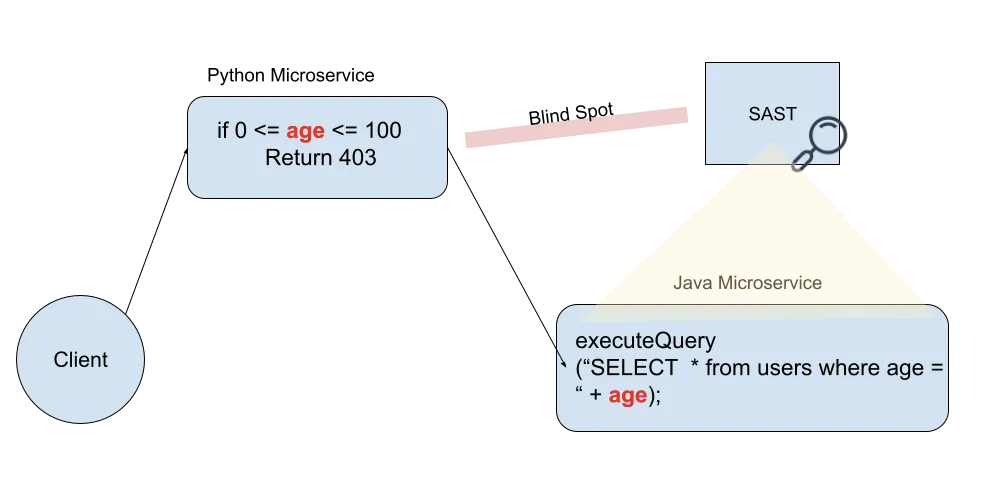
If the tool can’t identify all the places in the code where the input is validated, it can easily lead to many false positives.
The Final Showdown: SAST
The methodology for finding an exploitable vulnerability using code scanning contains three main processes:

The Advantages of SAST
- High coverage. SAST provides better code coverage per application than DAST and IAST (Interactive application security testing). SAST solutions can test many different flows without the need to generate traffic to trigger each one of them.
- Easy to launch. Most SAST tools don’t require much configuration before you launch a scan.
- Safe to use. Since SAST tools are passive by nature, you can casually run them without worry they will break your application.
The Challenges of SAST
- False positives. This is the main reason why security engineers struggle with SAST tools. Sometimes a simple scan leaves you with more questions than answers — an overwhelming report with many “vulnerabilities” that actually can’t be exploited because of input validation or unreachable code.
- Non-generic. If you use multiple programming languages and frameworks, more than one tool is probably needed. For a SAST company, the process of supporting a new language is long and cumbersome. It’s almost like building a new product.
- Library dependent. SAST tools can detect dangerous code patterns only in libraries and functions they are familiar with. An example: If your code uses less common or customized libraries for HTML rendering, there’s a good chance the tool won’t be able to identify XSS vulnerabilities.
- Lack of business logic context. SAST tools can’t find business logic vulnerabilities in the code itself, such as broken access control.
- Lack of production context. Some vulnerabilities can be found only when testing a running instance of the system, with all the components running in parallel.
About the Author
Inon Shkedy is Head of Research at Traceable.AI and a co-author of the OWASP Top 10 for APIs.
To learn more about Traceable AI and how it can help you better protect your applications and APIs you can watch a recorded demo.


.webp)