.avif)
Scaling the kafka consumer for a machine learning service in python



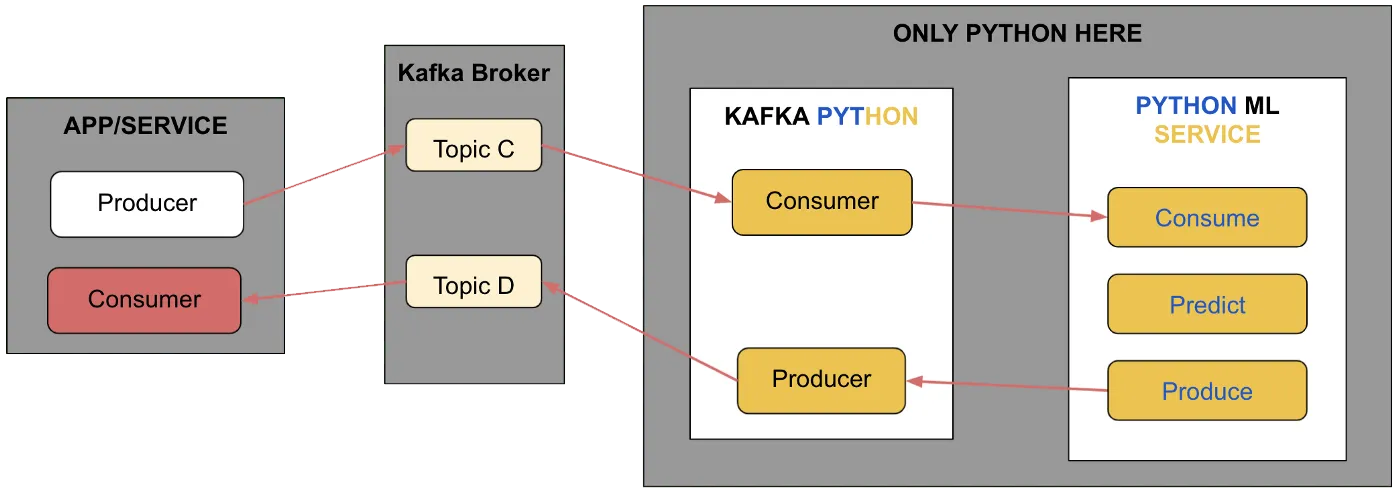
The Set Up
Imagine you are supposed to build a Python service using a machine learning model (trained offline) to detect if a web request is anomalous or not. The requests are coming at a rate of 1000 per second initially but will gradually increase as your main application reaches more customers. One can assume the requests to be like entries in the web logs and each request can have a potential attack. These requests are streaming in from a kafka consumer and need to be replied with a prediction to a Kafka producer.
We’re talking about some fast data here!
It goes without saying that we need to have a scalable ML service to match the speed of incoming requests. The point to note here is we are not dealing with big data but rather fast data during prediction time. Scaling the Kafka consumer horizontally by increasing the number of pods in a Kubernetes (K8s) cluster is a standard approach. But we can do much more than that. Also, our machine learning team mostly codes in Python may need to find a solution specific to the Python coding environment. If we have more tools and ways to tackle scalability within Python, one can also use such techniques for serving predictions for fast data on IoT devices, etc. with minimal distributed computing available.

Horizontal scaling is the same irrespective of the language used, due to the amazing benefits of installing a service in a Kubernetes cluster. You can increase the smaller configuration pods in the Kubernetes cluster and scale the Kafka-based service easily. However, there will be many scenarios where the infrastructure available is limited to deploy your Kafka-based service. For example, if the machines where the service is running have more CPUs(cores) available, it would make sense to use all of what is available. And also, it doesn’t make sense to spend heavily on multiple machines when a Kafka-based streaming platform is already burning a hole in your wallet. Hence, this thought exercise becomes more interesting only if we limit our discussion to what can be done when coding in Python.
Don’t be a bad fish
With the given set up above, we have three major problems to solve.
Consume fast, process fast, and produce fast.
If either of the steps is slow, the entire service can become a bottleneck to the overall company’s backend system.
For the scale (amount of data) or the rate of requests (fast data) we are discussing, a small function like consume, predict, or produce in a tiny ML service could cost the entire company a big customer!

Hopefully, we are convinced by now that we need to make all three of these functions fast with the lowest possible latency. For this exercise, we will limit our discussion to scaling the consuming part, and discuss process (predict) and produce in a separate piece.
Get to the point
In order to scale the Kafka consumer, we must also be aware of certain configurable settings or parameters which, if not handled properly, can lead to Kafka lags–basically extreme slowness of the consumer. So a brief on what those settings are:
- Auto commit configuration allows us to control if a consumer commits in background (asynchronous) or the user has to do it explicitly (synchronous). As a result, auto commit is not enabled, and there would be a certain blocking time before polling and processing for another message. Also, pointed out in the previous link, one can commit in batches with the appropriate message.
- Kafka consumer is consuming from a topic that can have the data in multiple partitions. One consumer can consume from multiple partitions. But when Kafka or the producer is distributing the data in multiple partitions, why not make multiple consumers consume in parallel from all the partitions? Though, it is useless to have a number of consumers more than the number of partitions, the number of consumers should at most match the number of partitions in an ideal scenario.
- Another important relevant property is the consumer group. Just like multiple partitions, there can be multiple consumer groups. You can read these two articles on how to leverage this property. I’ve not yet exploited multiple groups, so I’m not going to talk much about it here.
We will then leverage the Kafka properties in order to scale the consumer in Python.
Multiple Consumers via multiprocessing
The first way is to have multiple processes running–as many as the number of cores. This gives us as many consumers as possible on the same machine allowing the service to consume in parallel. Refer here below for the code.
from multiprocessing import Process
from confluent_kafka.avro import AvroConsumer
consumer_config = {'enable.auto.commit':True, 'bootstrap.servers':'localhost:9092', 'group.id':'group1' }
# Deliberately kept the config very simple
topic_name = 'raw_requests'
num_consumers = 4
def process_msg(msg):
# As per your your application, process the message
pass
def consume():
consumer = AvroConsumer(consumer_config)
consumer.subscribe(topic_name)
while True:
avro_msg = consumer.poll(1)
<Various checks and validation on the msg>
process_msg(avro_msg)
#consumer.commit() for synchronous commit
consumer.close()
def start_consumers(num_consumers):
for i in range(num_consumers):
process = Process(target=consume, args=())
process.start()
# Take care of restarting the process if it dies
return
The above code snippet shows how to start as many consumers as the value of num_consumers. This takes advantage of the multiprocessing module and starts a separate process for every consumer. There are multiple things in the above code which need to be taken care of. So please spend some time on different arguments to the function multiprocessing.Process().
Each consumer is nothing but an individual process in our case. So if we launch two different processes, both consuming messages in parallel, we effectively have two consumers consuming from two different partitions of the same Kafka topic.
Process messages in async via multi-threading
The purpose of doing this is to allow processing to become independent of consuming from the Kafka topic. In the above code snippet, you can notice the next poll cannot happen until the message processing (call to process_msg()) is complete. Consuming is blocked by processing. So, what is the solution?
Make processing independent of consuming by executing it in a thread. Though multithreading looks admirable at first glance,background threads in Python execute in concurrent mode but not in parallel. For us, parallel execution is taken care of by the multiple processors. To untie or decouple the processing from consuming, we have multiple threads such that
the consumer thread keeps queuing messages, and the process thread keeps dequeuing messages for processing. However, both are executing concurrently–not in parallel–with the benefit of both independent of each other!
Everything remains the same except processing the message from the consumer thread. We spawn a new thread for processing.
import threading
from queue import
Queueq = Queue(100)
def consume():
consumer = AvroConsumer(consumer_config)
consumer.subscribe(topic_name)
while True:
avro_msg = consumer.poll(1)
<Various checks and validation on the msg>
# process_msg(avro_msg)
q.put(avro_msg)
t = threading.Thread(process_msg, args=q)
# In process_msg, you can dequeue to process the message
#consumer.commit() for synchronous commit
consumer.close()
Again, note that I have made this extremely simple for explanatory purposes, but you will have to research how threads operate in Python and catc various exceptions like dead thread and starting a new thread, etc. As pointed out in this link:
Kafka consumer is not thread safe. Multi-threaded access must be properly synchronised. It is the responsibility of the user to ensure that multi-threaded access is properly synchronised.
Both the above tasks of having multiple consumers and decoupling processing and consuming demand an extra vigilance on the configuration settings of the Kafka consumer. One needs to look into settings like commit interval time (auto.commit.interval.ms), session timeout time (session.timeout.ms), maximum delay between poll (max.poll.interval.ms), etc. The incorrect setting of these parameters can lead to rebalancing of the consumer group, and thus slowing down your service as none of the consumers will work during the rebalancing task!
I will soon be writing on how to add a producer in the same service while keeping everything still working, and how to train and predict faster with a simple ML model like SVM. The effort on those tasks will be comparatively less as once the messages are consumed, it is under the control of your service on how to process and how to produce.
Conclusion
In the end, remember the following:
At any moment of a service processing the data consumed from a Kafka consumer, there are only two main operations taking place — consuming and processing. If either of the operation is executed synchronously, it blocks the other operation. Auto commit configuration in Kafka consumer allows us to keep polling the data asynchronously. This benefit, when combined with multi-threading in Python, allows us to process asynchronously.
In other words, the auto commit feature lets the polling continue. If processing is taking some time, then there is a high chance of Kafka lag building up! Therefore, we also need to take care of the processing such that it doesn’t block from consuming messages. Python’s multithreading comes to the rescue.
Not all ML engineering problems are about handling big data; there’s also streaming fast data. ;)
Some references for further reading:
Source code for kafka.consumer.multiprocess
Concurrency and parallel execution
https://www.confluent.io/blog/kafka-consumer-multi-threaded-messaging
The Inside Trace
Subscribe for expert insights on application security.


.webp)
